人工智能如何突破“黑箱”? ——对于大数据分析和资管行业的赋能

导语
以人工智能技术开发商业大数据,实现投资组合管理优化。

一直以来,科技进步都是推动资管行业发展的重要力量。随着大数据等技术的发展,人工智能时代离我们越来越近,新的科技也对传统的投资组合管理方法提出了挑战。
过去70年,投资财富管理领域一直由诺贝尔经济学奖得主哈里·马科维茨(Harry M. Markowitz)引领的均值-方差优化法(mean-variance optimization) 占主导地位。大数据时代,这一方法面临明显的瓶颈。
这一传统方法要求投资者首先对资产回报的分布进行估算,再根据风险收益偏好和操作便捷程度进行决策。由于第一步估算存在严重偏差,且无法系统性地考虑到投资者动态资金局限和交易成本等因素,该方法一直为人所诟病。同时,现代金融数据具有高维度、高噪声、非线性等特点,传统计量经济学手段对于数据中的信息提取十分有限,很难把握其中的非平稳动态和复杂的交互作用。不过,现在AlphaGo、Siri等人工智能中的深度神经网络强化学习模型可以有效解决这些问题,大数据和人工智能技术的发展为投资财富管理决策提供了新的思路和前景。
当前,大数据以前所未有的数量、维度和频率喷薄而出,并且在大量决策场景中以传统数据源(如调查或财务报告)的替代补充形式出现。这些原始数据具有复杂且不规律的结构(如卫星图片、语音和视频、文本、移动足迹等)。与此同时,机器学习与人工智能算法作为大数据分析方法大量涌现。随着大数据与人工智能迅速渗透到社会生活的各个层面,传统上依靠人为判断的决策受到深刻影响,如雇用决定、贷款赠款、刑事判决、财务建议等。
数据生成方式和“黑箱”问题限制AI赋能金融
虽然科技的发展催生了大量的数据,但社会科学中的数据生成过程不同于自然科学中的数据生成。虽然高维和非线性的金融数据与科学和工程学中的大数据高度相似,但与科学数据相比,业务或财务数据往往具有更低的信噪比和更高的稀疏性,并伴有较多内生变量之间的交互作用。
与此同时,我们必须认识到,与人体基因序列或自然科学原理不同,商业环境和市场在快速发展、高频演变,政策也随之不断变化,代际之间的行为也不尽相同。我们不能将现有的机器学习软件包和大数据分析盲目地投入对经济和金融问题分析的应用。经济大数据和机器学习的现有应用只能为模型的取信和调整提供有限的参考,许多方法必须在了解商业和经济学原理的基础上进行改良。
与此同时,基于大数据的人工智能算法经常被描述成一个无人理解的“黑箱”,人工智能算法的可解释性问题时常被提起。尽管数据处理技术不断更新迭代,但人工智能和大数据分析对历史数据仍存在严重依赖。同时,大数据和人工智能模型往往对特别对象,尤其是经验上处于不利地位的对象产生相当偏见(见表1)。
表1 知名人工智能系统的内在偏见
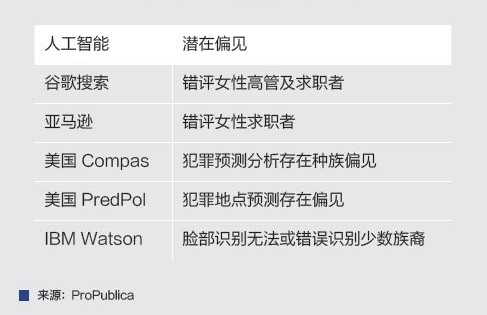
例如,在图片识别模型的构建过程中,研究者需要对大量的图形文件手动标记并归类。在一些人脸识别系统的训练过程中,由于少数族裔的图片数据缺失,研究者发现模型可以正确识别近99%的白人测试者的性别,却只能正确识别65%的黑人测试者。这样的误差证明了人工智能的设计过程仍存在诸多问题和缺陷。
在更严肃的应用场景中,人工智能的潜在偏见可能造成严重后果。在美国多州司法裁判中广泛使用的人工智能Compas系统体现了这类偏见的危害性。在判决及量刑过程中,Compas系统会根据嫌疑人对一系列问题的回答估计嫌疑人的“再犯率”。在一些判决中,Compas对有三次持械抢劫犯罪史的白人盗窃犯打出了3分(较低可能再犯),而对仅有四次未成年轻罪的黑人盗窃犯打出了8分(极有可能再犯)。由于Compas系统算法及逻辑并未公开,该系统的使用虽然一定程度上提高了司法速度,但是仍然造成了许多误判,并在美国法律界引起了争议。
人们通常将偏见问题归因于人工智能的训练数据。然而算法设计人员对人工智能的校正以及人工智能的反馈很有可能加剧使用者的偏见。这样的可能性并未引起模型设计者足够的重视。从数据收集到理论假设,人工智能模型往往包含了大量由历史偏见、随机错误和意识形态造成的偏差。模型还可能迎合用户的沉迷和偏执而诱发不当行为。
解决此类问题首先要了解各种机器学习模型的经济学原理。然而,大部分相关模型具有显著的“黑箱”特性,对于模型的因果关系及经济学原理释义仍十分有限。这也影响了机器学习在经济、金融等社会科学应用中的推广。
“强化学习”优化投资组合
强化学习(Reinforcement Learning)是人工智能领域的重要分支。在强化学习中,施教者通过设定策略网络来对模型根据环境做出的行动提供奖惩信息,以达到强化训练的目标。强化学习在计算机视觉、语音识别、自动驾驶等领域已经获得了广泛的应用。而在社会科学领域中,相较于已经被广泛研究的监督学习和无监督学习,强化学习的应用仍处于起步阶段。
强化学习在投资组合优化问题上有很强的应用性。强化学习擅长解决投资组合优化问题包含的诸多随机决策。通过调整奖惩机制和绩效函数,强化学习可以精准解决投资者的不同需求,如对高夏普比率进行奖励并对过度借贷策略进行惩罚。与其他专注于提高收益的算法相比,强化学习算法具有更高的灵活性和针对性。在Cong等2019年和2020年连续推出的论文[1]中, 作者们通过一系列先进的人工智能技术对强化深度学习的金融应用进行发掘,发明了AlphaPortfolio人工智能和序列学习等投资模型。
一方面,基于跨资产神经网络及注意力机制提高了参数准确度。AlphaPortfolio的模型使用了600余个资产信息作为输入参数,其中包括股指回报率、资产收益率、买卖价差等。在此基础上,作者们将多个不同资产输入神经网络(图1)。模型将根据策略机制和输入参数为所有相关资产打分。所生成的投资组合将重仓高分资产,同时空仓低分资产。通过模型,AlphaPortfolio生成的投资组合确保了较高的收益和较低的波动,并在各种经济条件限制下维持高于2.0的夏普比率。
其中,注意力机制(Attention Mechanism)就被作者们加以改良为扩资产注意力网络(Cross-asset Attention Network)。在翻译长句中的某一单词时,一般的模型会赋予长句中所有单词相同的权重,然而,目标单词本身理应获取较句中其他词语更高的权重。在投资组合模型的应用中,注意力机制使我们对资产的评分更专注于单一资产本身的参数,减轻了组合中其他资产对评分公允性的影响。
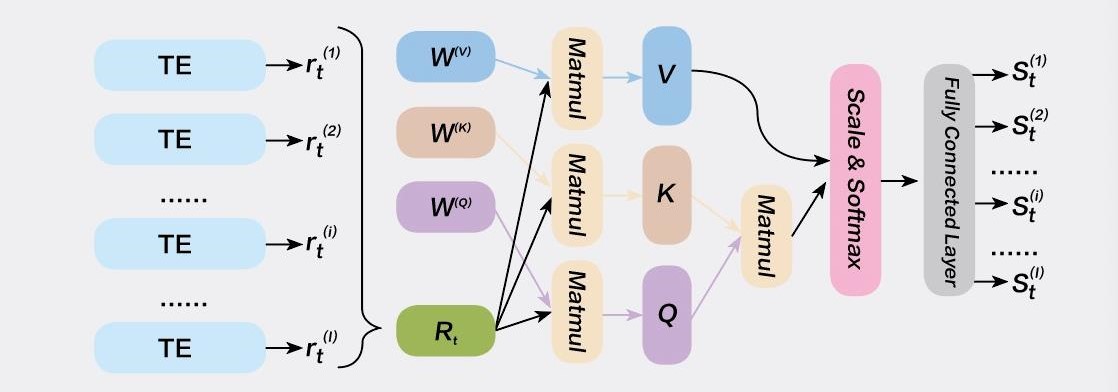
图1 神经网络模型
另一方面,通过多项式敏感度可以分析解读模型的经济学意义。由于机器学习与神经网络模型通常具有较高维度和非线性等特点,使用者往往在理解模型背后的经济意义时遭遇困难。而多项式敏感度分析可以将高维度的非线性模型投影到多项式模型上,并逐一分析资产参数对模型评分的贡献度(见图2)。结果显示,库存、税前利润率、现金资产率等参数对评分具有较显著的作用。这些结果与其他投资研究的成果一致,并对模型的参数选择提供了重要参考。
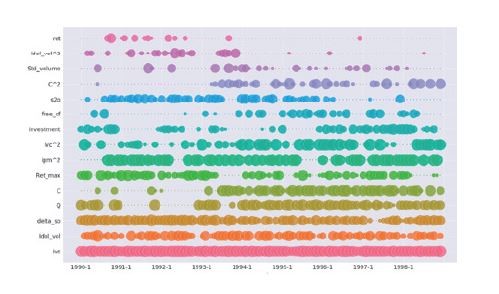
图2 参数贡献度演化(1990—1998年)
文本因子 “对话”人工智能
与数值数据不同,文本数据由自然语言组成,因此也具有比数值数据更优越的可解释性。通过自然语言处理算法,我们可以更好地理解人工智能机器学习模型,找到其潜在的主题及逻辑(见图3)。Cong等(2018)[2]所开发的文本因子体系便提供了一种有效的利用文本空间解读大数据人工智能应用的途径,也是AlphaPortfolio所采用的一种经济解读。
从上市公司的季报或年报文档以及财报会议记录出发,自然语言处理算法先将原始文本转换成数值向量,再将数值向量进行聚类,最终,在各个聚类上建立文本因子。这种以数据驱动的分析模式可以拆分复杂的语言结构,并且确保使用者有能力解释人工智能模型产生的结果,并将模型应用于不同行业、不同背景的上市公司。在上文所述的模型中,在季报与年报中谈及销售、利润和企业发展规划的公司往往收获高分,而强调房地产及经营失误的公司则经常收获低分。自然语言处理技术可以显著提高使用者对于模型结果的理解。

图3 文本数据比数值数据具有更优越的可解释性
除了解读资管模型,文本因子在社会科学中也有广泛的应用。文本因子结合自然语言处理中前沿的人工智能工具,其对应的分析框架在社会科学中也有广泛应用。例如,之前提及的Cong等(2018)的文章中介绍如何用新闻生成文本因子来预测如GDP增长和失业率等宏观指标,或是度量创新;又如Cong等(2020)[3]中结合了专业知识和数据驱动的两种方法,用文本因子生成高维度的公司治理和创新的指标, 不仅弥补了传统度量单一缺准和无时间序列变化等问题,同时也发现了新的治理维度,并可以应用到公司股东投票结果等的预测中。Cong等(2020)[4]中更详细描述人工智能在社会科学中充满拓展空间及因子结构如何可以更好开发非结构化数据。
注释:
[1] Cong, Tang, Wang, and Zhang, AlphaPortfolio for Investment and Economically Interpretable AI, 2019. Cong, Tang, Wang, and Zhang, Deep Sequence Modeling: Development and Applications in Asset Pricing, 2020.
[2] Cong, Liang, and Xiao, Textual Factors: A Scalable, Interpretable, and Data-driven Approach to Analyzing Unstructured Information, 2018.
[3] Cong, Foroughi, and Malenko, A Textual-Factor Approach to Measuring Corporate Governance, 2020.
[4] Cong, Liang, Yang, and Zhang, Analyzing Textual Information at Scale, 2020.
*本文经原作者授权,仅代表作者个人观点。