大模型来袭,证券行业或迎变革?

导语
大模型研发浪潮下,证券行业能否把握行业变革带来的发展机遇是能否构建长期核心竞争力的关键。

国内首批11家大模型产品陆续通过备案,大模型发展驶入快车道,生产力工具迎来颠覆式革新。证券行业天然具备数字化优势,与大模型应用层面落地存在高度适配性。然而,目前大模型在证券行业业务场景的探索处于迭代升级初期。大模型研发浪潮下,证券行业如何把握行业变革带来的发展机遇是能否构建长期核心竞争力的关键。因此,本文尝试探究大模型的发展变革及其应用落地模式,探寻金融行业与大模型融合的应用场景,并以证券行业为锚点,畅想“券商 + 大模型”发展远景图、业务落地可行性以及可能面临的挑战,为券商把握大模型革新机遇提供借鉴与参考。
大模型发展颠覆式变革
大模型(LLM) 是 大 规 模 语 言 模 型(Large Language Model)的简称,是“大数据 + 大算力 + 强算法”的产物。大模型是能够借助大数据和神经网络来模拟人类思维和创造力的人工智能算法和利用海量参数的深度学习模型,通过“预训练—有监督微调—反馈强化学习”来理解、生成和预测新内容。
国内外大模型发展变革
与早期人工智能模型相比,现有阶段的大模型在参数规模、算法结构、商业模式以及应用场景等方面均特色显著,逐步从识别、筛选等感知能力,向理解、分析、决策等认知能力转变,推动学习泛化能力、认知互动能力完成了质的飞跃,生成式人工智能(Artificial Intelligence Generated Content,AIGC)使LLM 成为人类生产力工具革新的驱动力。
首先,参数规模倍数级增长,多模态预训练模型占据主流。作为一种深度学习算法,大模型的快速发展伴随着参数规模的激增,先后经历单语言预训练模型、多语言预训练模型、多模态预训练模型三个阶段。在“参数为王”时代,高频训练量超越阈值之后可以带来模型精准度的质变,各大商家开始寻求模型参数设置量级的丰富化。例如,腾讯“混元”大模型达到了千亿级参数,阿里“通义千问”大模型则官宣已达到10万亿参数。
其 次,Transformer 架 构 提 出, 自 然 语 言 处 理(Natural Language Processing,NLP) 开 启 新 范 式。Transformer是一种基于 Attention 机制的序列模型,与传统的循环神经网 络(Recurrent Neural Network,RNN) 和 卷 积 神 经 网 络(Convolutional Neural Networks,CNN)等深度学习模型不同的是,在引入注意力机制和并行计算思想之后,其 Transformer能够实现“知识识别—内容生成”的系统服务,有效解决长序列数据记忆处理难题。这也是研发者开启对扩充大模型参数量的追逐的主要原因。目前大模型参数设置的白热化之争或只适合于边际效应递增的发展初期,参数设置饱和后,运算效率和性能提升或将达到峰值,因此重点是如何契合并落地至具体应用场景。
大模型应用层面落地模式分析
综观全球大模型应用层面的竞争格局,美国凭借算法模型集成研发和产品化的领先优势,整体呈现头部巨头通用模型领先、中小厂商聚焦垂类场景特色的发展格局。国内大模型的发展相对较晚,互联网巨头以其在AI领域的长久积累具备先发优势,随着高校研究院、人工智能企业等组织/主体积极进入大模型的“蓝海”领域,国内大模型应用将日趋成熟。
应用场景是大模型发展的核心驱动力和价值释放地。通用模型和行业模型的商业应用现处于研发迭代的早期阶段,未来大模型的变现模式主要有 To B(To Business)和 To C(To Consumer)两个渠道。通用模型运算过程中只涉及少量微调,适合完成多场景任务、泛化普适性功能。行业模型前期需要运用行业知识进行大批量训练,更加注重专业适用性,以契合不同行业的特色需求。
To B 端变现模式:一是做公有云,通过大模型调用实现,以token方式收费,是典型的API(Application Programming Interface)模式;二是专注私有云部署,通过定制化服务收费;三是做大模型平台,提供算力、评测等系列服务,由于服务覆盖面更广,百度、商汤、阿里等大型企业涉猎可能性更大。To C端落地变现模式:一是提供具备生产力工具的AIGC 产品,随后通过产品外部订阅收费;二是提升产品使用体验,重视模型与市场现有产品的交互契合度,后续基于用户流量向商家端进行收费变现。
国内金融行业大模型应用初探
金融行业属于信息密集型行业,具有天然数字化的优势,大模型在认识互动、文本生成、交易决策、计算推理等性能方面的跨越式提升,具备与金融行业多个应用场景的高度适配性。[1]
AI 大模型与金融不是技术的简单糅合,而是针对不同业务场景的业务流创新(见图1)。当前既有在银行、保险、证券等金融行业的应用,又有聚焦具体业务板块,探索更垂直化、颇具使用深度的服务:①大模型 + 行业领域Bloomberg GPT是首个全方位提供金融信息和财经资讯的垂直和通用混合范式的大模型,能够赋能多种金融应用场景;恒生电子专为金融行业打造的大模型Light GPT, 具备金融专业问答、逻辑推理、超长文本处理、多模态交互等能力,能够为投顾、客服、投研、运营等金融业务场景提供底层AI能力支持。②大模型+细分业务:摩根士丹利将GPT-4接入财富管理业务,打造涵盖市场投资策略、财经资讯、研究报告等内容的财富管理智库,投资顾问人员可以通过与聊天机器人深度互动,实现高效便捷的信息统计分析。

大模型与证券行业深度融合
大模型在金融业务场景的应用层面落地多集中在智能问答等1.0时代,随着金融行业“数据 + 人才 + 技术”与AIGC等大模型应用的深度融合,该融合有望成为金融行业转型升级的新引擎。证券行业凭借业务的高灵活性、强机动性和多创新性,或可抢先实现AI大模型 + 券商落地,为智能分析、量化交易、智能投顾和合规风控等业务注入新活力。
从现实展望未来:应用场景革新的机遇
根据大模型发展特点、券商各业务板块展业需求和二者深度融合可行性,笔者试图将券商与大模型的融合划分为三个时代。
秉承“能落地、可应用”的核心准则,关注应用场景革新,笔者认为当前“券商 + 大模型”正处于1.0—2.0时代的过渡期。
1.0时代:简单场景化辅以弱交互属性,赋能C端的初步探索。
该阶段聚焦的业务场景相对简单,大模型主要以认知、理解能力为主,交互属性相对较多,能够满足券商在服务C端客户的初步探索的需求。受限于人工智能发展,券商与科技的结合仍然是以实现专业知识智能问答和金融插件工具内部接入为主,如打造“数智员工”、智能开户以提升对于C端客户的服务效率。同时,通过外部金融插件的接入,能够快速实现券商内部数据资料筛选、图表制作等需求。
2.0时代:模型标准化与服务差异化共存,打造To B服务范本。
随着垂类大模型发展趋于标准化,券商将会更加关注服务模式的差异化,客户赋能也从C端逐步覆盖机构端,开始重视打造具备AI特色的To B业务功能。例如,恒生电子打造的智能投研平台WarrenQ,以及各机构接入GPT完善量化投资交易工具。在2.0时代,投研、投行、投顾、交易等各业务模块的专研大模型竞相推出,市场将会开始关注“傻瓜交易”、网格指令的普惠性和公平性,而券商自有 App 将不再局限于机制式的问答和操作,而是能够实现更加智能的交互对话,通过分析海量的市场数据和用户行为,为用户提供更加精准的投资建议,实现风险管理和合规监控的智能化。
3.0时代:个性化与普适化,打通一站式全流程系统
券商大模型的终极形态应该是全面化、个性化和普惠化的场景体现,是通用大模型与垂类大模型协同发展的产物,能够在一个平台实现前中后业务的有效联通,为客户提供一站式平台化服务。在这种情况下,券商与大模型的融合度达到100%,“数据 + 算力 + 算法”的部署趋于成熟,数据合规、黑盒边界等问题将得到有效解决。券商内部数据系统被打通,各系统间调用通畅,既能针对单一客户的信息输入输出训练提供个性化服务,又能确保业务流趋于普惠化,大模型全方位渗透加码以提升客户服务体验。
业务落地可行性:赋能买方投顾业务大有可为,重资源业务更新迭代优先级低
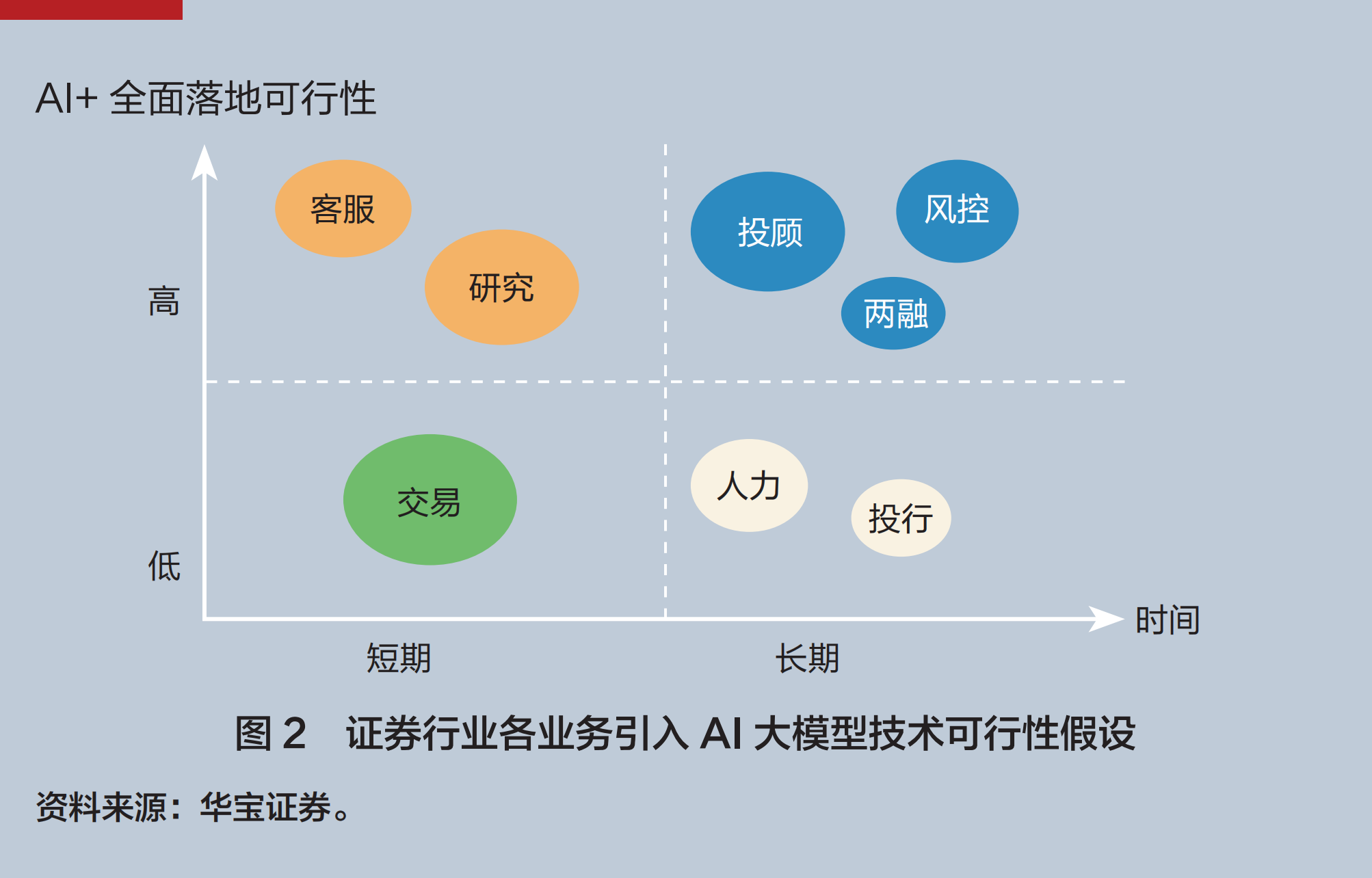
若从业务落地可行性来看,垂类大模型可以在证券行业自动化客户服务、研究、量化交易、智能风控、融资融券和投行等应用场景相继落地。笔者根据大模型 + 业务全面落地可能性和落地所需时间,将各个业务划分在四个象限。具体分析如下:
短期内在证券行业中最容易、最便捷、相对成本最低的落地项目是研究业务。券商接入模型的API接口,即可辅助研究报告的底层数据收集、基本逻辑的梳理和金融建模的代码等,减轻研究员冗余的基础性、重复性工作压力,让研究员有更多观点思考产出,提升对数据和事件点评报告的产出速度。
短期可试用、难全面推广的是交易业务。机器学习和深度学习模型兼顾稳健性、透明性以及模型时序预测能力和拟合度,可在交易指令创建、记忆、转化、修正等方面进行结合。盘前资讯收集整理、观点输出;盘中实时因子计算、模型预测、投资组合管理、动态调仓;盘后总结归纳、业绩归因。动态优化量化交易策略,通过大规模多样化的市场数据训练,预测股票价格和市场趋势,实现策略的动态实时修正。例如,针对B端量化客户,通过大模型API端口接入,券商根据交易策略对标的股票池进行筛选,快速响应客户需求并创新。大模型可以在纯量化策略上深度应用,但对于主观量化这种本身需要介入决策者主观意识的交易策略而言,大模型的应用仅能局限在筛选、回撤、归因等事务性工作上,终究无法赋予主观意识。
长期来看,大模型与券商买方业务结合更具适配性,尤其是在买方投顾等财富管理领域大有可为。买方投顾业务发展是金融行业的发展“蓝海”,其重点在打造投资、顾问以及平台三大方面。笔者认为财富管理的终极生态是买方投顾。现在券商与大模型的合作也多集中于财富管理领域,应用场景落实在前文提到的智能投研内容生成、个性化理财需求的困惑解答、投资服务深度陪伴以及特定任务的智能化处理方面。监管多次提及独立投资顾问机构发展,畅想未来,若以美国投顾发展为鉴,在买方投顾驱动下,独立注册投资顾问(Registered Investment Advisors,RIA)的发展空间极为广阔。随着财富管理领域的投资咨询、账户管理、资金运营等业务被专业化机构细分后赋予牌照,大语言模型等技术可以和买方投顾机构深度融合,实现商业盈利模式的革新,从依靠产品到依靠服务,再到依靠SaaS订阅、运营分成、流量收费。
TAMP(Turnkey Asset Management Platform)模式是买方投顾,既是独立投顾深化发展的必经之路,也是大模型在财富管理领域发力的主要锚点。TAMP平台能够提供投资决策与系统运营等全流程服务,具体包括共同基金、ETF(Exchange Traded Fund)、特定账户在内的投资解决方案,同时提供会计对账、业绩披露、税务优化、信息报告等后台运营服务。AIGC等大模型产品的应用,能够跨模态生成个性化内容,通过大数据串联“投资 + 研究 + 电商”三大模块,以技术为支撑、信用为保障,通过多轮互动,融入多模态知识理解,加快TAMP 模式快速落地,大模型的发展终将成为TAMP模式构建的重要组成部分。目前该部分发展仍处于行业空白,发展空间广阔,未来各券商如能推出更加智能化、个性化和高效化的 LLM来服务TAMP模式和投顾业务,可以帮助券商降本增效,并从当下传统业务的困境中脱颖而出,在竞争激烈的买方业务市场中占据一定份额。
笔者认为,大模型和券商业务并不能实现全面融合(见图2)。就当前场景应用市场而言,大模型虽然可以赋能投行等强资源依赖性业务,但全面融合落地可能性较小,或只能在中台承做方面有所作为。例如,建立数据仓库,优化入池、筛选、簿记等流程化工作及持续期管理等。考虑到投行、资管等业务的承揽和承销环节更加看重从业人员的客户资源和揽客能力,现有大模型应用的底层逻辑依旧是工具化属性,多是赋能长流程、复杂化、重复式工作,将人员从简单的工作中释放出来,主观意识输出和人情世故处理的大模型终不能胜任。
应用层挑战:关注技术要求、数据合规和监管变革
文心、星火、通义等国内大模型ToC端应用多停留在对话、智能搜索、“数智人”等初级阶段,支持AIGC领域文案创作、文本生成、知识问答等能力①;To B端虽有部分开源模型推出,也逐步融入多模态知识理解,但单个模型的普适性和应用性仍需拓宽,在技术、数据、监管三大方面仍存在发展“桎梏”。
第一,技术要求:完善基础设施建设,确保信息的及时性、准确性、专业性。
大模型对证券公司的基础设施建设提出较大挑战。金融领域知识具有强专业性,证券公司需要重构知识的输入端模型,识别客户文字信息的有效字段,确保客户的需求意图,模型设立后也需要大量预训练反馈,底层算力需求投入成本较高,正式全面投入使用的过程也较为繁杂。而且从输出端来看,金融领域的知识输出需要满足高效性、及时性、精确性要求,对于大模型预训练信息需要及时更新,提升对于数据选择、处理、改造的工程化能力,防止出现训练语料滞后的问题。
应用场景和技术发展“一体两翼”,两者呈现相互催化、迭代进步的相生关系。大模型与证券业的深度融合,需要黏性强、量极大、频次高的应用场景加以匹配。如果仅将大模型应用于投研决策、智能客服、风险管理、智库建设、业务审核等场景,“大而全”的通用模型或许有些大材小用,“小而美”的垂类模型更适配。在2.0时代,证券行业通过“大模型 + 券商”构建贴合业务的全指标体系,针对大场景、客户画像进行标签化管理,细分垂直模型的应用和交互,才能逐步走向3.0时代的全流程融合,但该阶段对底层架构的构建和应用场景的打通要求都较高。对于中小券商而言,技术成本带来的压力将会降低机构整体参与度,能否平衡大模型接入带来的成本和效益,是能否引发行业深度革新的关键。
第二,数据安全:分设对内对外接口,关注数据合规与归属权管理。
随着大模型竞品层出不穷,各类产品问答中针对训练数据集讳莫如深,数据安全和使用权被摆上高位,数据是产品差异化的重中之重。
对外部客户服务的大模型产品,除了宏观数据公布、上市公司数据披露、交易所数据公开等公共的数据库,证券公司如何搭建大模型产品训练数据付费模式成为竞争的关键点。试想机构资源丰富的券商是否推出了“知情人士透露数据库”“一手行业调研数据库”“聪明散户交易数据库”,还有已在运行的“市场认可度较高的分析师报告”“投顾策略组合优选”“金融产品的投研评价”等模式的迭代升级,证券行业财富管理业务的竞争必然朝着付费模式化、数据资源化、金融科技化的方向前进。
对内部赋能的大模型产品,需要考虑涉及跨部门数据调配、信息隔离墙设置、涉密信息外部端口阻拦等方面配置,目的是提升券商各部门“文案办公”的效率和准确性,辅助检查和监督,使从业人员更加专注于服务质量,简化服务流程,节省服务时间,允许证券公司把更多的精力和资源投入到拓客业务、人员和GPT融合程度培养上,进而实现降本增效和盈利增长的目的。
第三,监管发力:放和管两手抓,重视三大流程监管。
2023年8月15日,《生成式人工智能服务管理暂行办法》正式实施,鼓励生成式人工智能技术在各行业、各领域的创新应用,生成积极健康、向上向善的优质内容,探索构建应用场景生态体系。中国作为首个针对生成式人工智能产品应用出台管理办法的国家,保持了对创新业务一贯的监管态度,即鼓励的、开明的、支持的,但强合规且审慎管理的,即降低事前准入,强化事中事后监管。现阶段,中国垂类大模型应用落地较少,监管部门尚需明确细化对引入海外大模型的合规性管理,尤其是对垂类行业模型的监管,由于涉及数据合规问题,因此不仅涉及中华人民共和国工业和信息化部等顶层算力监管部门,还需要地方层、行业主管部门介入。由此,大模型的广泛落地,一定需要先补足大模型各衍生分支的监管框架,对标准制定、数据安全与治理双管齐下。
证券行业作为金融领域较为可能广泛使用大模型的拓路者,监管不仅需要把握“放”和“管”的结合与平衡,还要精准划定“管”的程度与边界,秉承“全程管、适度放”的原则,将“业务 + 过程 + 人员”三大流程的监管相结合,持续进行反馈改进,促进行业良性竞争。
(1)业务监管:鼓励投资者参与证券业务的全流程管理,针对数据治理等建立投资者申诉维权机制;
(2)过程监管:实时监测大模型对投资者的反馈结果,定时发布大模型发展应用状况;
(3)人员监管:规范立法监督行业人员不会利用大模型进行违规操作;
(4)反馈改进:通过课题、圆桌会议、协会讨论等形式吸收改进不足之处,强化事中事后监管的积极作用。
展望:以开放心态参与,积极迎接变革
大模型研发潮流涌进,证券行业注定迎来大变革,尤其是证券行业发展差异化逐步消弭,业务同质化越发严重,券商立足金融垂类大模型发展已是大势所趋。无论是内部研发,还是从第三方采购,都需要避免盲目冒进,注重大模型与业务场景的适配性,细分专业领域并不需要超大规模的模型,不恰当的网络架构设计反而会造成对计算资源的极大浪费。此外,需要更加关注数据敏感性,明确公有云和私有云的部署划分,强化合规评估与风险管理。监管介入,重点关注大模型产品引入后对数据安全、黑盒性质、监管边界发展的影响,审慎运用金融科技渗透各业务领域,实现证券行业高质量发展。未来大模型是成为C端用户的服务流量入口,还是成为 B 端机构客户的底层技术支撑,仍需时间加以检验。
注释:
[1] 李振. 应用才是硬道理,下半年发布证券行业智能助手[N]. 21世纪经济报道,2023-07-31(018).
[2] 赵大伟.AIGC能力本质与应用场景[J].企业管理,2023(09):42-45.
*本文仅代表作者个人观点,仅供读者参考,并不作为投资、会计、法律或税务等领域建议。编辑:葛雯瑄。